机器学习(Machine Learning)是让计算机能够自动地从某些数据中总结出规律,并得出某种预测模型,进而利用该模型对未知数据进行预测的一种方法。它是一种实现人工智能的方式,是一门综合了统计学、概率论、逼近论、凸分析、计算复杂性理论等的交叉学科。
在机器学习中,一般将样本分成独立的三部分训练集(train set),验证集(validation set)和测试集(test set)。其中,训练集用于建立模型,测试集用来检验最终选择最优的模型的性能如何。
模式识别是机器学习中通过数学方法来研究模式处理的一类问题;数据挖掘是从数据库管理、数据分析、算法的角度探索机器学习问题;而统计学习则是站在统计学的视角来研究机器学习问题。
机器学习大致可以分为以下几类:
- 有监督学习(Supervised learning)
- 无监督学习(Unsupervised learning)
- 半监督学习(Semi-supervised learning)
- 强化学习(Reinforcement learning)
监督学习 学习一个模型,模型能够对任意给定输入,对其做出一个好的预测。输入与输出
机器学习问题的一般流程:数据收集 –> 数据预处理 –> 特征工程 –> 模型的选择 –> 模型的评估
Hacker News的热门排名算法
Hacker News 是一家关于计算机黑客和创业公司的社会化新闻网站,没有踩或反对一条提交新闻的选项,只可以赞或是完全不投票。Hacker News 允许提交任何可以被理解为“任何满足人们求知欲”的新闻。
Hacker News 采用公式 (p – 1) / (t + 2)^1.5 做为排行依据。其中P是投票数量,t是发表以来的时间,小时计。在其他条件不变的情况下,得票越多,排名越高。
为什么是P-1?很多文章作者在提交的时候会给自己投上一票。文章发布初期的投票数对排名影响非常大,仅仅是给自己投一票,也会起到非常大的作用。换在国内,估计P-100还不够。
其他条件不变的情况下,越是新发表的帖子,排名越高。
重力因子G的数值大小决定了排名随时间下降的速度。G主要目的是控制更新频率。G的值越大,score的衰减速度越快,排行的更新越频繁。
Reddit的排名算法
Reddit 与 Hacker News有很大的不同点就是,Hacker News文章标题前面只有一个向上的小箭头,即只能投赞成票,而Reddit的每个文章标题前会有两个箭头,即一个向上,一个像下。分别代表“赞成”与“反对”。
Reddit 排名算法主要与以下内容有关:
- 文章的发表时间t: t = 发表时间 – 2005 年 12 月 8 日7:46:43
- 赞成票与反对票的差x: x = 赞成票 – 反对票
- 投票方向y
- 帖子的受肯定程度z
《社交网络》中Facemash算法分析
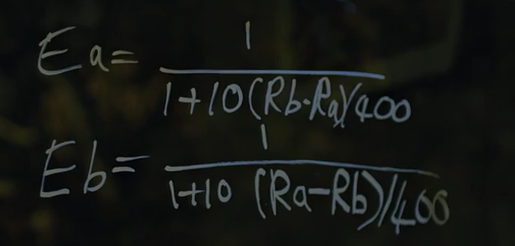
推荐系统
推荐算法通常被分为四大类:
- 协同过滤推荐算法
- 基于内容的推荐算法
- 混合推荐算法
- 流行度推荐算法
梯度下降(Gradient Descent)
- 梯度
- 梯度下降与梯度上升
- 梯度下降的直观解释
- 梯度下降的相关概念
- 梯度下降法的代数方式描述
- 梯度下降法的矩阵方式描述
- 梯度下降的算法调优
集成学习原理
集成学习(ensemble learning) 是通过构建并结合多个机器学习器来完成学习任务。
对于训练集数据,通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众长的目的。集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器。
个体学习器
第一种就是所有的个体学习器都是一个种类的(同质)。
第二种是所有的个体学习器不全是一个种类的(异质)。
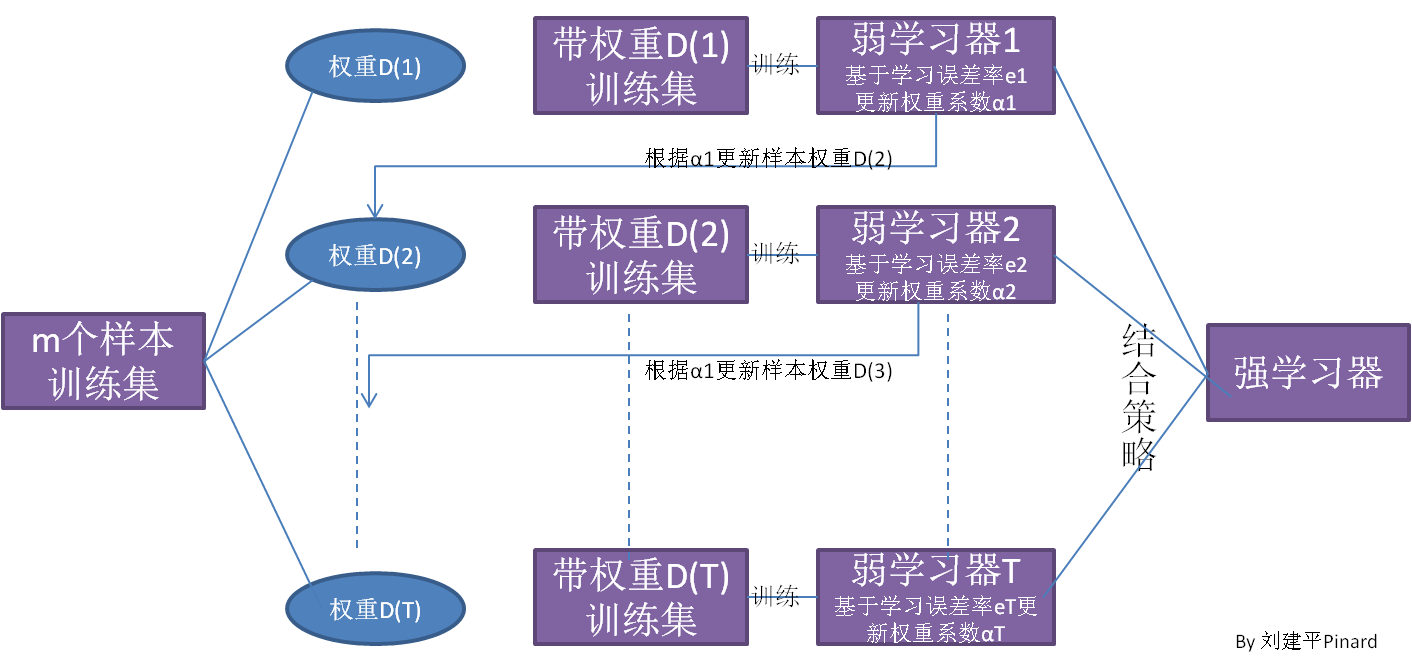
Boosting
Boosting算法工作机制:首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree)。
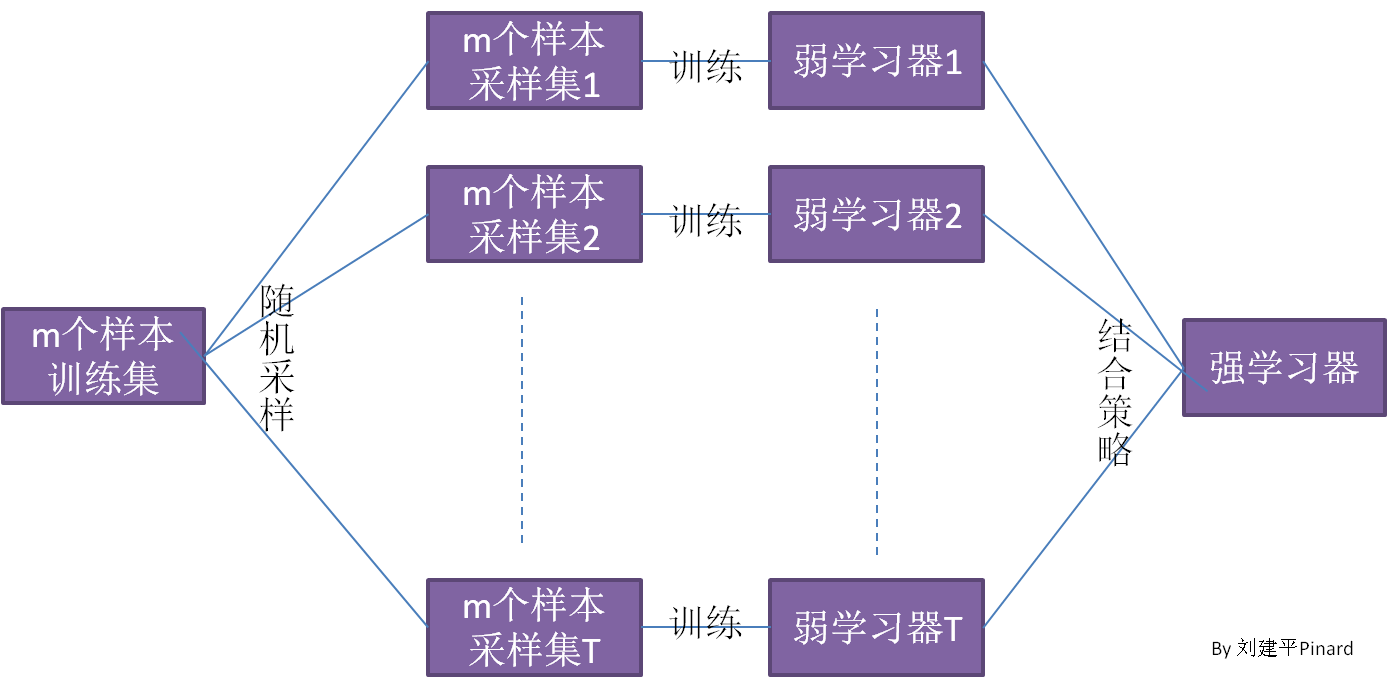
Bagging
Bagging的个体弱学习器的训练集是通过随机采样得到的。通过T次的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略来得到最终的强学习器。
结合策略
平均法
数值类的回归预测问题,通常使用的结合策略是平均法。
对于若干个弱学习器的输出进行平均得到最终的预测输出。
投票法
分类问题预测,通常使用投票法。
假设预测类别是{c1,c2,…cK},对任意一个预测样本x,T个弱学习器预测结果分别:(h1(x),h2(x)…hT(x))。
最简单的投票法是相对多数投票法,(少数服从多数)。T个弱学习器对样本x的预测结果中,数量最多的类别ci为最终分类类别。如果不止一个类别获得最高票,则随机选择一个做最终类别。
稍微复杂的投票法是绝对多数投票法,(票过半数)。相对多数投票法的基础上,不光要求获得最高票,还要求票过半数。否则会拒绝预测。
更加复杂的是加权投票法,和加权平均法一样,每个弱学习器分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
学习法
Adaboost
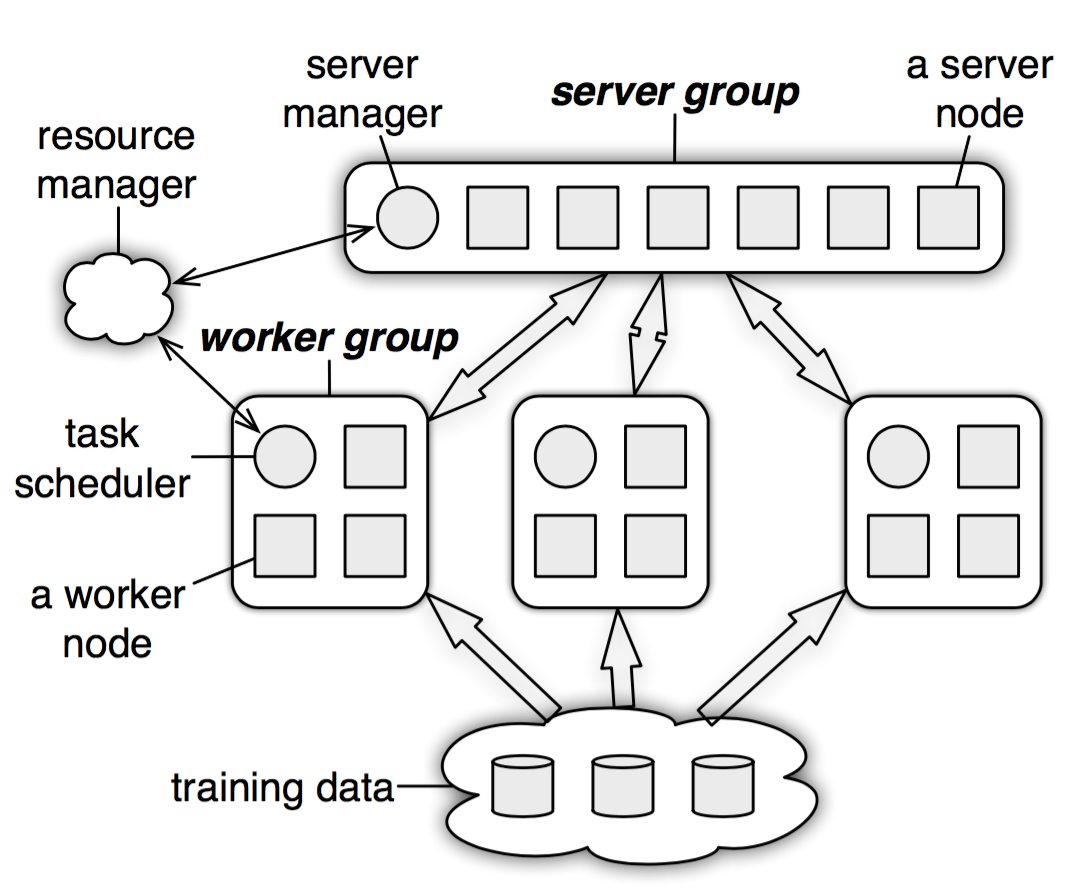
Parameter Server
KNN (k-nearest neighbor)
Reference: