Apache Flink是目前业界公认最好的流计算引擎之一,其计算能力不仅仅局限于做流处理,而是一套兼具流、批、机器学习等多种计算功能的大数据引擎,用户只需根据业务逻辑开发一套代码,无论是全量数据还是增量数据,亦或者实时处理,一套方案即可全部支持。
Apache Flink 的定义、架构及原理
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行快速计算。
- Streams: 分为有限数据流与无限数据流,无限数据流的数据会随时间的推演而持续增加,计算持续进行且不存在结束的状态,相对的有限数据流数据大小固定,计算最终会完成并处于结束的状态。
- State: 状态是计算过程中的数据信息,在容错恢复和 Checkpoint 中有重要的作用,流计算在本质上是 Incremental Processing,因此需要不断查询并更新状态;另外,为了确保 Exactly- once 语义,需要数据能够写入到状态中;而持久化存储,能够保证在整个分布式系统运行失败或者挂掉的情况下做到 Exactly- once,这是状态的另外一个价值。
- Time: 分为 Event time、Ingestion time、Processing time。时间是我们判断业务状态是否滞后,数据处理是否及时的重要依据。
- API: 由上而下可分为 SQL / Table API、DataStream API、ProcessFunction 三层
有状态的流式处理
传统批处理方法持续收取数据,以时间作为划分多个批次的依据,再周期性地执行批次运算。假设需要计算每小时出现事件转换的次数,如果事件转换跨越了所定义的时间划分,传统批处理会将中介运算结果带到下一个批次进行计算;除此之外,当出现接收到的事件顺序颠倒情况下,传统批处理仍会将中介状态带到下一批次的运算结果中,这种处理方式也不尽如人意。
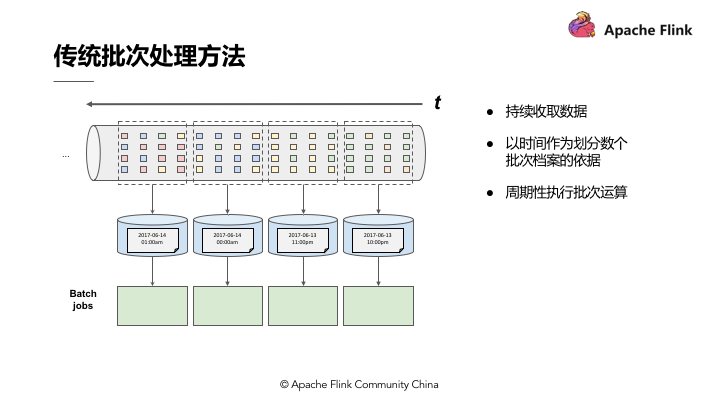
引擎必须要有能力可以累积状态和维护状态,累积状态代表着过去历史中接收过的所有事件,会影响到输出。
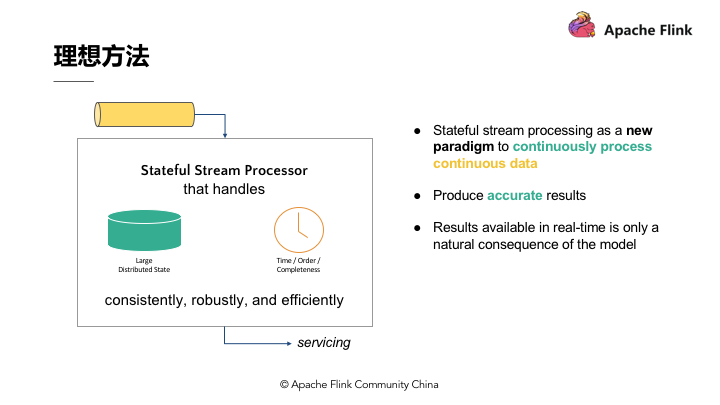
时间意味着引擎对于数据完整性有机制可以操控,当所有数据都完全接受到后,输出计算结果。
理想方法模型需要实时产生结果,但更重要的是采用新的持续性数据处理模型来处理实时数据,这样才最符合 continuous data 的特性。
DataStream API
Apache Flink 提供了 DataStream API 来实现有状态的流处理应用程序。Flink 支持对状态和时间的细粒度控制,以此来实现复杂的事件驱动数据处理系统。
Flink Maven Archetype:
1 | mvn archetype:generate \ |
Reference: